open函数除了> >> <这三种最基本的文件句柄模式,还支持更丰富的操作模式,例如管道。其实bash shell支持的重定向模式,perl都支持,即使是2>&1这种高级重定向模式,perl也有对应的模式。
打开管道文件句柄
perl程序内部也支持管道,以便和操作系统进行交互。例如,将perl的输出在程序内部就输出给操作系统的命令,或者将操作系统的命令执行结果输出给perl程序内部。所以,perl有2种管道模式:句柄到管道、管道到句柄。
例如,将perl print语句的输出,交给操作系统的cat -n命令来输出行号。也就是说,下面的perl程序和cat -n命令的效果是一样的。
#!/usr/bin/perlopen LOG,"| cat -n" or die "Can't open file: $!";while(){ print $_;}
再例如,将操作系统命令的执行结果通过管道交给perl文件句柄:
#!/usr/bin/perlopen LOG,"cat -n test.log |" or die "Can't open file: $!";while(){ print "from pipe: $_";}
虽然只有两种管道模式,但有3种写法:
- 管道输出到文件句柄模式:
-| - 文件句柄输出到管道模式:
|- |写在左边,表示句柄到管道,等价于|-,|写在右边,等价于管道到句柄,等价于-|,可以认为"-"代表的就是外部命令
上面第三点|的写法见上面的例子便可理解。而|-和-|是作为open函数的模式参数的,以下几种写法是等价的:
open LOG, "|tr '[a-z]' '[A-Z]'";open LOG, "|-", "tr '[a-z]' '[A-Z]'";open LOG, "|-", "tr", '[a-z]', '[A-Z]';open LOG, "cat -n '$file'|";open LOG, "-|", "cat -n '$file'";open LOG, "-|", "cat", "-n", $file;
而且,管道还可以继续传递给管道:
open LOG, "|tr '[a-z]' '[A-Z]' | cat -n";
但是涉及到两个管道的时候,输出到终端屏幕上时可能不太合意:
[root@xuexi perlapp]# perl 15.plx test.log [root@xuexi perlapp]# 1 A 2 B 3 C
如何让输出不附加在shell提示符后,我暂时也不知道如何做。
但是,输出到文件中不会出现这样的问题:
open LOG, "|tr '[a-z]' '[A-Z]' | cat -n >test2.log";
[root@xuexi perlapp]# perl 15.plx test.log[root@xuexi perlapp]# cat test2.log 1 A 2 B 3 C
更多关于open和管道的解释参见:。
以读写模式打开
默认情况下:
- 以
>模式打开文件句柄时,会先截断文件,也就是说无法从此文件句柄关联的文件中读取原有数据,且还会清空原有数据 - 以
>>模式打开文件句柄时,首先会将指针指向文件的末尾以便追加数据,但无法读取该文件句柄对应的文件数据
如何以"既可写又可读"的模式打开文件句柄?在Perl中可以在模式前使用+符号来实现。
结合"+"的模式有3种,都用来实现读写更新操作。它们的意义如下:
+<:read-update,如open FH, "+<$file",可以提供读写行为。如果文件不存在,则open失败(以read为主,写为辅),如果文件存在,则文件内容保留,但IO的指针放在文件开头,也就是说无论读写操作,都从开头开始,写操作会从指针位置开始覆盖同字节数的数据。+>:write-update,如open FH, "+>$file",可以提供读写行为。如果文件不存在,则创建文件(以write为主,read为辅)。如果文件存在,则截断整个文件,因此这种方式是先将文件清空然后写数据,再从中读数据。+>>:append-update,如open FH, "+>>$file",提供读写行为。如果文件不存在,则创建(以append为主,read为辅),如果文件存在,则将IO指针放到文件尾部。一般情况下,每一次读操作之前都需要通过seek将指针移动到文件的某个位置,而写操作则总是追加到文件尾部并自动移动指针到结尾。
一般来说,要同时提供读写操作,+<是最可能需要的模式。
1.打开可供读、写、更新的文件句柄,但不截断文件
open LOG,"+<","/tmp/test.log" or die "Couldn't open file: $!";
如下面的例子,say语句会将数据写入到test.log的尾部,因为遍历完test.log后,指针在文件的尾部。
#!/usr/bin/perluse 5.010;open LOG,"+<","test.log" or die "Couldn't open file: $!";while(){ print $_;}say LOG "from hello world";
但注意,如果将上面的say语句放进while循环,则会出现读、写错乱的问题,因为+<模式打开文件句柄时IO指针默认在文件的开头:
#!/usr/bin/perluse 5.010;open LOG,"+<","test.log" or die "Couldn't open file: $!";while(){ print $_; say LOG "from hello world";}
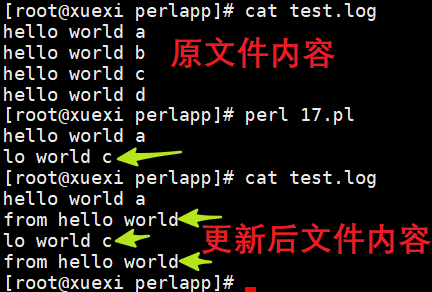
分析下这个错乱:当读取了第一行后,放置好指针位置,然后赋值给$_并被print输出,然后再写入"from hello world",写入的位置是指针的后面,它会直接更新后面对应数量的字符数。数一数"from hello world"的字符数量和替换掉的字符数量,会发现正好相等。
2.打开可供读、写、更新的文件句柄,但首先截断文件
open LOG,"+>","/tmp/test.log" or die "Couldn't open file: $!";
因为首先会截断文件,无法直接去读取内容。所以,这种操作模式,需要首先向文件中写入数据,再去读取数据。
#!/usr/bin/perluse 5.010;open LOG,"+>","test.log" or die "Couldn't open file: $!"; say LOG "from hello world1"; say LOG "from hello world2"; say LOG "from hello world3";while(){ say $_;}
3.打开可供读、追加写的文件句柄。它不会截断文件。
open LOG,"+>>","/tmp/test.log" or die "Couldn't open file: $!";
因为追加写模式会将指针放置在文件尾部,如果不将指针移动到文件的某个位置(可通过seek来移动),将无法读出数据来。
例如:
#!/usr/bin/env perluse strict;use warnings;use 5.010;open LOG,"+>>","test.log" or die "Couldn't open file: $!";say LOG "from hello world1";say LOG "from hello world2";say LOG "from hello world3";while(){ print "First: ", $_; # 啥也不输出}seek(LOG, 0, 0); # 将读指针移动到文件开头while( ){ print "Second: ", $_; # 正常输出}
open打开STDOUT和STDIN
如果想要打开标准输入、标准输出,那么可以使用二参数格式的open,并将"-"指定为文件名。例如:
# open LOG, "-"; # 打开标准输入open LOG, "<-"; # 打开标准输入open LOG, ">-"; # 打开标准输出
没有类似的直接打开标准错误输出的方式。如果有一个文件名就是"-",这时想要打开这个文件而不是标准输入或标准输出,那么需要将"-"文件名作为open的第三个参数。
open LOG, "<", "-";
创建临时文件
如果将open()函数打开文件句柄时的文件名指定为undef,则表示创建一个匿名文件句柄,即临时文件。这个临时文件将创建在/tmp目录下,创建完成后将立即被删除,但是却一直持有并打开这个文件句柄直到文件句柄关闭。这样,这个文件就成了看不到却仍被进程占用的临时文件。
什么时候才能用上打开就立即删除的临时文件?只读或只写的临时文件都是没有意义的,只有同时能读写的文件句柄才是有意义的,所以open的模式需要指定为+<或+>。显然,+<是更为通用的读、写模式。
例如:
#!/usr/bin/perluse strict;use warnings;# 创建临时文件open my $tmp_file, '+<', undef or die "open filed: $!";# 设置自动flushselect $tmp_file; $| = 1;;# 这个临时文件已经被删除了system("lsof -n -p $$ | grep 'deleted'");# 写入一点数据say {$tmp_file} "Hello World1";say {$tmp_file} "Hello World2";say {$tmp_file} "Hello World3";say {$tmp_file} "Hello World4";# 指针移动到临时文件的头部来读取数据seek($tmp_file, 0, 0);select STDOUT;while(<$tmp_file>){ print "Reading from tmpfile: $_";} 执行结果:
perl 22685 root 3u REG 0,2 0 108086391056997277 /tmp/PerlIO_JHnTx1 (deleted)Reading from tmpfile: Hello World1Reading from tmpfile: Hello World2Reading from tmpfile: Hello World3Reading from tmpfile: Hello World4
内存文件
如果将open()函数打开文件句柄时的文件名参数指定为一个标量变量(的引用,即下面示例中标量前加上了反斜线),也就是不再读写具体的文件,而是读写内存中的变量,这样就实现了一个内存IO的模式。
#!/usr/bin/perl$text = "Hello World1\nHello World2\n";# 打开内存文件以便读取操作open MEMFILE, "<", \$text or die "open failed: $!";print scalar;# 提供内存文件以供写入操作$log = ""open MEMWRITE, ">", \$log;pritn MEMWRITE "abcdefg\n";pritn MEMWRITE "ABCDEFG\n";print $log;
如果内存文件操作的是STDOUT和STDERR这两个特殊的文件句柄,如果需要重新打开它们,一定要先关闭它们再重新打开,因为内存文件不依赖于文件描述符,再次打开文件句柄不会覆盖文件句柄。例如:
close STDOUT;open(STDOUT, ">", \$variable) or die "Can't open STDOUT: $!";
perl的高级重定向
在shell中可以通过>&和<&实现文件描述符的复制(duplicate)从而实现更高级的重定向。在perl中也同样能实现,符号也一样,只不过复制对象是文件句柄。
例如:
open LOG,">&STDOUT"
表示将写入LOG文件句柄的数据重定向到STDOUT中。
shell中很常用的一个符号是>&FILENAME或>FILENAME 2>&1,它们都表示标准错误和标准输出都输出到FILENAME中。在perl中实现这种功能的方式为:(注意dup目标使用\*的方式,且不加引号)
open LOG,">","/dev/null" or die "Can't open filehandle: $!";open STDOUT,">&",\*LOG or die "Can't dup LOG:$!";open STDERR,">&",\*STDOUT or die "Can't dup STDOUT: $!";
或者简写一下:
open STDOUT,">","/dev/null" or die "Can't dup LOG:$!";open STDERR,">&",\*STDOUT or die "Can't dup STDOUT: $!";
测试下:
use 5.010;open LOG,">>","/tmp/test.log" or die "Can't open filehandle: $!";open STDOUT,">&",\*LOG or die "Can't dup LOG: $!";open STDERR,">&",\*STDOUT or die "Can't dup STDOUT: $!";say "hello world stdout default";say STDOUT "hello world stdout";say STDERR "hello world stderr";
会发现所有到STDOUT和STDERR的内容都追加到/tmp/test.log文件中。
如果在同一perl程序中,STDOUT和STDERR有多个输出方向,那么dup这两个文件句柄之前,需要先将它们保存起来。需要的时候再还原回来:
# 保存STDOUT和STDERR到$oldout和OLDERRopen(my $oldout, ">&STDOUT") or die "Can't dup STDOUT: $!";open(OLDERR, ">&", \*STDERR) or die "Can't dup STDERR: $!";# 实现标准错误、标准输出都重定向到foo.out的功能,即"&>foo.out"open(STDOUT, '>', "foo.out") or die "Can't redirect STDOUT: $!";open(STDERR, ">&STDOUT") or die "Can't dup STDOUT: $!";# 还原回STDOUT和STDERRopen(STDOUT, ">&", $oldout) or die "Can't dup \$oldout: $!";open(STDERR, ">&OLDERR") or die "Can't dup OLDERR: $!";
因为这种高级重定向用的很少,所以不多做解释。如需理解,可参考我的shell关于高级重定向的文章:,或者直接参考Perl的高级重定向文章:。